AXYS Editorial

- Axys Data Storage Service integrates data from various sources to enhance automation capabilities.
- Combining multiple data sets allows for deeper insights beyond individual platform functionalities.
- Creating a data pipeline requires careful planning and resources for effective data modeling.
- Axys simplifies data integration with no-code solutions for quick connectivity to data sources.
- The platform's architecture supports real-time, batch, and big data use cases across environments.
- Developers can easily create custom connectors, enhancing the platform's functionality and integrations.
Bring data and automation together with Axys Data Storage Service. Give your automation program the data capabilities it needs to thrive.
Different teams require different sets of data from specific sources to build their daily reports. Sales, marketing, and product reports are generated from their data sources. However, these reports can be generated mostly from their associated platforms like Salesforce for sales, HubSpot for marketing, etc.
What if the company needs to discover more insight by combining two data sets? One from Salesforce and another from HubSpot? Sure, we can integrate these two directly despite the maintenance and effort needed to perform analytics on data. But what if the third-party solution uses these two data sets to complete a task not defined in Salesforce or HubSpot functionalities?
What if combining data from ten or fifty sources is required to depict insight? Yes, it is virtually impossible to create one-to-one integration between many sources, and none of these platforms will fully support functionalities to take advantage of the other applications’ integration.
To partially resolve this, companies must go through a comprehensive practice to create a pipeline from their structured or unstructured data (multiple data sources) and transform data into the data warehouse. Then create a sophisticated model to transform and build relationships between data models to distinguish between sales datasets, customer datasets or product datasets, and more.
They can produce sales, marketing, or product reports through another sophisticated process. For data modeling, significant resources and planning are required. The building blocks are the planning of business requirements in advance, data modelers, DBA and engineering resources, and the building blocks for data like data warehousing. Designing building blocks for data modeling (entities, attributes, and relationships) is essential since future changes can be extremely costly and time-consuming.
According to Oracle, data modeling process workflow requires conceptual modeling where business requirements gathering happens. In this process, the data entity must be defined, and relationships and attributes to be set for future use. The second step is logical modeling, where we need to apply data model patterns and create data requirements.
The third process is physical modeling, where technical requirements are set, and performance requirements are analyzed. All these will lead to the database as the fourth step, where business data are defined and placed to create and update the databases. These databases will be used to organize and produce all the data needed for different business units, such as Sales, Marketing, Business, or products. These final data can be shared with other mediums or channels such as applications, API layers, storage, and more.
But is this solution suitable for every organization? Absolutely not. Typically, organizations using data warehousing need to generate tremendous amounts of data to make it work for their needs. Naturally, very large organizations can only satisfy this requirement. The modeling and warehousing also require experienced knowledge workers and experts in-house.
Not only during development but also while maintaining it, the model needs to be modified. Another major problem is that if an organization needs to add, remove, or replace more data sources, most of the process needs to be re-evaluated and might trigger significant developments.
Many companies falsely adopt this solution while their requirements can be achieved with other thoughtful ones that make life easy for everyone. The best is making a no-code solution to add data sources in minutes. Automate data collection and store them in a way that is easily accessible and low-cost to store. The system must be able to transform and package data based on the requirements demand and allow any solutions to be built on top of that data layer access.
Axys platform has developed a solution to satisfy all these requirements with the minimum resources required. With Axys, connection to data sources such as SaaS applications, databases, and many more have been automated fully and takes a few minutes to connect. After connection, data will be organized by a no-code interface to build the required schema of the type necessary to satisfy business requirements.
These are called smart profiles (entities), such as People, Customers, Projects, Products, customs, and more. Axys also allows admins to dynamically create and name these profiles and assign objects and data from the source connected (attributes). After profile setup, the system will schedule to index data at a given time.
Axys enterprise-grade architecture utilizing data virtualization techniques and data fabric exclusively joined:
- Axys data virtualization architecture allows the integration of data sources quickly and efficiently without any limits. It creates a virtual abstraction layer by eliminating data silos and connecting all data sources. It provides a universal layer across different applications such as SaaS, on-premise, and more within your company data environment. Axys enables multiple heterogeneous data stores and distributed databases to be viewed and accessed as a single database within the auto-generated API layer provided.
- So, rather than physically performing ETL/ELT on data with transformation engines, Axys data virtualization platform performs data extraction, transformation, and integration virtually. Axys also creates an abstraction of IT resources that masks their physical nature and boundaries from resource users. Axys data fabric is an environment consisting of a unified architecture and services with many integrated technologies running on that platform that helps organizations manage their data.
- The ultimate goal of Axys data fabric is to maximize the value of your data and accelerate digital transformation. Axys data fabric is used to simplify data discovery, governance, and active metadata management. The data can be processed, managed, and stored as it moves within the data fabric. The data can also be accessed by or shared with internal and external applications or custom build tools and solutions for a wide variety of analytical and operation use cases for all organizations.
In summary, Axys as a data virtualization and data fabric platform:
- Connects to any data source via pre-packaged connectors and components, eliminating the need for coding and manual integration
- Provides data ingestion and integration capabilities – between and among data sources as well as applications
- Supports batch, real-time, and soon, big data use cases
- Manages multiple environments – on-premises, cloud, hybrid, and multi-cloud – both as a data source and as a data consumer
- Provides built-in data quality, data preparation, and data governance capabilities, strengthened by Elasticsearch to improve data discovery and auto keyword mapping
- Supports data sharing with internal and external stakeholders via proprietary auto-generated API secured by a token.
- Automatically tag data (tag management) to build many-to-many relationships between data indexed.
- Axys proprietary auto-generation API layer allows admins to automatically get access to all profiles (entities) that have been created instantly and being able to retrieve all data (attributes) indexed.
Axys provides many functionalities to manage and retrieve your organization’s data most effectively and efficiently. The Axys provides:
- Advance elastic search
- Tagging to dig into information
- Advanced filtering options for large-size data
- Create new objects from existing combinations
- Advance reporting for usage and indexing
- Allow building historical data change (Data Journey)
- The capability of building any application solution on the API layer
- Auto API Layer Generator as any source is connected.
- Advance indexing options. Weekly, Daily, hourly, and streaming
- Health monitoring system
- Ability to write back to the source (Special permissions are required)
- Export data indexed to any format (JSON, CSV, and more)
- Ability to modify the indexing and mapping logic within the code (Axys Approval required)
- Ability to decentralize and add your connector (Axys Approval is needed)
- Fully automatic Private Cloud Deployment. Setup time is approximately 13 minutes with highly scalable, maintainable, extensible, and reliable architecture.
- Near to no maintenance requirements due to auto maintenance for the system environment.
- For more information and capabilities, please contact Axys.
Axys & Developers
Axys is a developer-friendly platform. As we build our developer community, we prepare the foundation for those individuals. Developers can take advantage of the freemium model of Axys provided in the AWS marketplace (Coming Soon). The lite version of Axys, allows developers to create and add their own specific connector to the marketplace after quick approval requirements from Axys.
For example, if Axys is not offering a connector for QuickBooks Online; yet, developers can use our detailed guided development documentation to create and add it to the marketplace. Axys has developed a sophisticated way of integration that will reduce the time to make connectors to just a few days. Developers don’t have to complete the API integration from the SaaS application since, In most cases, the only requirement for Axys is to establish the connection between Axys and the source added. Axys can read and demonstrate the most standard schema of the SaaS platforms.
For example, if the developer codes the authentication part of QuickBooks and deploys the connector, Axys most likely finds the objects and fields from QuickBooks API and allows them to be viewed and selected for indexing. By choosing these fields in the no-code admin view interface, Axys will collect all the data from those fields and create relationships among data at the given indexing schedule.
After the connectors are deployed, and in use, a developer can dynamically select the fields from one-to-many sources and allow Axys to index, combine and transform the data for its internal persistence storage. Upon indexing, Axys automatically generates and updates the API layer for developers to access the data collected. Developers can use the JSON output from the REST API layer (other output types are available) to build desktop, mobile or cloud applications.
In the past few months, Axys has brought many experience developers together to serve Axys customers with solution developments. Since these developers have a vast knowledge of the Axys system, they can help your organization reach its solution development millstone as fast as possible with a deeply discounted rate.
Breaking Down Data Silos with Automated Integration
Automated integration takes much of the burden off of the technical staff by handling the numerous manual tasks required to incorporate siloed data.
Here is an example of how the Axys platform can help you resolve your integration and data accessibility problems in a matter of minutes.
- The first time, deploy access to your corporate environment. Have the SSL and some environment information available. The process is fully automated—just four lines of command lines. Total time spent is not more than 30 min, including installation.
- Alternatively, login to your environment setup by the Axys team free of charge.
- Log in to your portal. Select an application from the marketplace. I.e., Salesforce. Enter your credentials and click Connect. Add the second and more connections. I.e., Jira, MS Teams. Total time spent for each connector setup. 1-2 min.
- Select pre-field profiles (entities) (People, Customers, and more). Review pre-selected fields (attributes). Add more attributes coming from the connector and name the variables. I.e. Under Salesforce, Select the attribute (Employee Active City), and Provide any variable name (EmployeeActiveCity_SF). When done with the selection, click save. You can repeat this process for every source as much as you need.
- All the data fields you added will be immediately available after the first index in the Axys REST API for the call.
- Enjoy all your data access from now on. If you need to add or remove data, please repeat step 3.
- Axys REST API layers allow you to call attributes for any reason, such as manipulation or calculation, to create new attributes.
- For example, if a developer needs to create a value for ROI that doesn’t exist in the system, call for Net income and Cost of investment attributes and use the formula ROI = (Net income / Cost of investment) x 100. Use the (EmployeeActiveCity_SF) values to sort ROI from a specified team/group by city (profit center).
- Many other features will be immediately available to explore, such as advanced search, advanced filtering, reporting, system report, health report, and many more proprietary features.
- Never be worried about how to integrate, digest, transform and access data ever again.
Frequently asked questions
Everything you need to know about AXYS Platform
AI, LLM, Prompting, and Search
Data Management and API Features
General AXYS Platform Overview
Integration and Connectivity
AI, LLM, Prompting, and Search
AXYS offers a no-code approach to AI prompting and model integration, making it simple for any user to connect data and interact with AI models. The platform intelligently analyzes your connected data schemas and suggests optimized prompts tailored to your unique data structure, helping you get more accurate and relevant results from AI models like OpenAI. AXYS can even use its own built-in AI to refine or enhance your prompts, automatically generating the most effective questions and responses for your use case. This seamless process allows businesses to integrate powerful AI and LLM capabilities without manual coding, complex engineering, or guesswork—accelerating AI adoption and improving outcomes.
Data Management and API Features
AXYS automatically detects and harmonizes data schemas from all your connected sources, standardizing field names, data types, and relationships for unified analysis. You can further customize schema mapping with intelligent or manual tagging, overwrite field names, and create relationships between sources—all through a no-code interface. AXYS also supports advanced data transformation, letting you condition, enrich, and adapt data to fit your business needs. This flexibility ensures your structured and unstructured data is always ready for analytics, AI, and workflow automation.
AXYS automatically detects and maps data schemas from all connected sources, standardizing field names, data types, and relationships for unified analysis. In addition to automatic harmonization, AXYS offers intelligent and manual tagging options, lets you overwrite field names, and allows you to create custom relationships between sources or fields—all with no code required. These flexible tools make it easy to tailor your data model, combine complex data sets, and adapt transformations for your specific business needs. Whether you need fully automated mapping or hands-on customization, AXYS ensures your data is always organized, consistent, and ready for advanced analytics or AI projects.
General AXYS Platform Overview
AXYS is an all-in-one, no-code data orchestration platform designed to unify, clean, and connect all your business data—whether structured or unstructured—from databases, files, SaaS applications, and more. Unlike traditional data integration tools that often require months of engineering and complex coding, AXYS can be deployed and start delivering value within days. The platform automatically generates secure, AI-ready APIs, connects instantly to a wide variety of data sources, and prepares your data for advanced AI and large language model (LLM) projects. With AXYS, even non-technical teams can manage, analyze, and optimize data quickly and efficiently, removing engineering roadblocks and accelerating AI adoption for your business.
Integration and Connectivity
Yes, AXYS integrates seamlessly with popular SaaS platforms such as Salesforce, QuickBooks, and many others. Connecting to these platforms usually takes just a few minutes with a simple, no-code setup. Once connected, AXYS automatically detects and imports the schema, allowing you to select specific fields, apply conditions, and organize the data as needed. You can then instantly build as many customized API endpoints as your business requires, unlocking flexible data access, automation, and AI-powered analytics—all with minimal effort and no engineering required.
Adding or removing data connectors in AXYS is a simple, no-code process. You only need to provide your authentication credentials, and AXYS automatically connects to your data source, verifies the integration, and continuously monitors the connection for health and reliability. No engineering or manual setup is required, so you can easily manage all your connectors from a user-friendly interface. This makes it quick and effortless to update, expand, or streamline your data integrations as your business needs change.
AXYS comes ready to connect with a wide range of popular databases, file storage services, SaaS applications, and cloud platforms. Out of the box, AXYS supports connectors for Microsoft Azure, AWS RDS and S3, MySQL, Google Workspace, SharePoint, Salesforce, Jira, QuickBooks, HubSpot, BambooHR, Okta, FreshDesk, Google Analytics, Authorize.net, PayPal, Constant Contact, CSV and Excel files, and more. If you have a source not currently listed, AXYS can easily add new connectors based on customer needs or popular demand, ensuring compatibility with virtually any business system.
Latest
From the blog
The latest industry news, interviews, technologies, and resources. View all posts
Top 5 Checklist for Enterprise Search and Data Fabric Integration
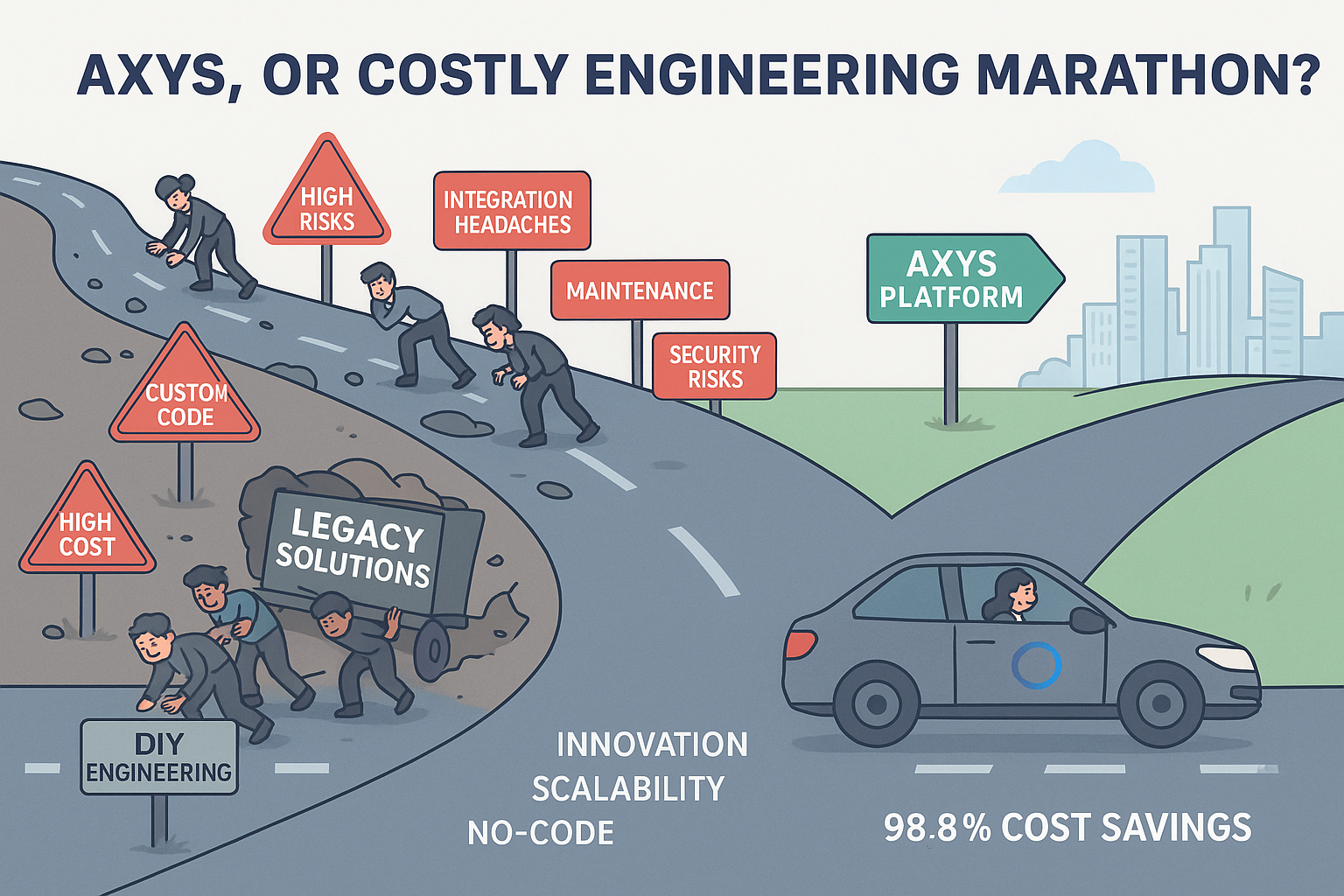
AXYS, Or Costly Engineering Marathon?
